 国际站
国际站 在学术界,如何评价一位研究者的长期影响力?
- 只看论文数量,无法体现其质量。
- 只看总引用次数,又可能因为一两篇“爆款”论文而被过分拔高,无法反映其持续的贡献能力。
为了解决这个问题,物理学家乔治·赫希(Jorge E. Hirsch)在2005年提出了H指数(h-index)。它是一个旨在同时衡量研究者**学术产出的“数量”(productivity)与学术成果的“影响力”(impact)**的综合性指标。
第一部分:H指数的定义
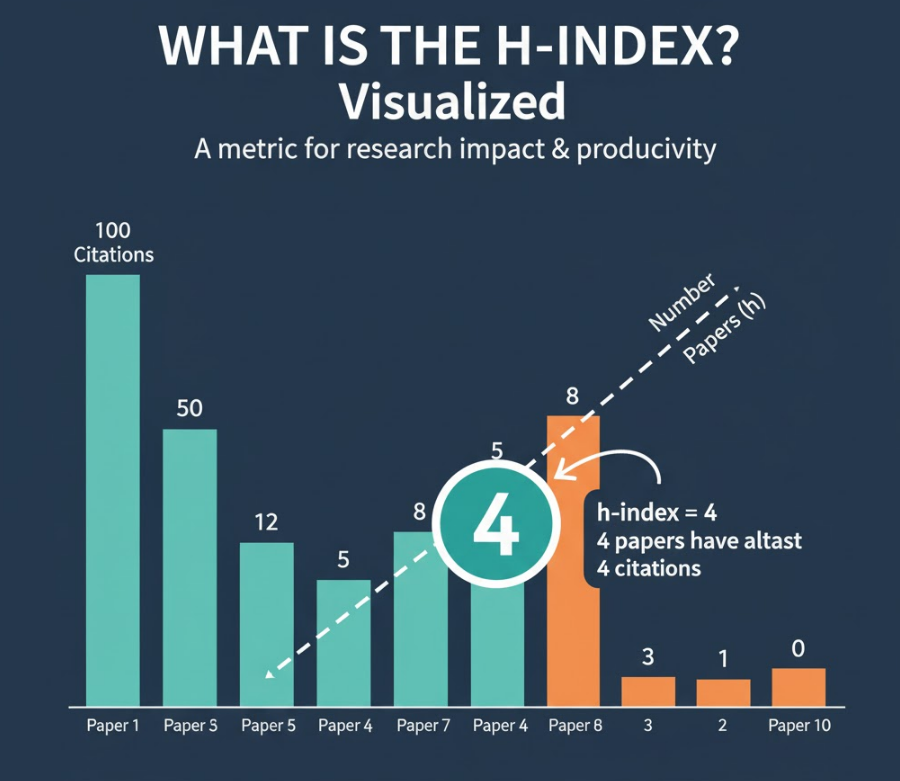
官方定义: 一位学者的H指数是指,在其所有发表的论文中,有 h 篇论文,分别被引用了至少 h 次,而其余的论文,其引用次数都不超过 h 次。
这个定义听起来有些绕口,我们可以用一个更简单的方式来理解。
通俗理解: 如果你的H指数是10,就意味着你至少有10篇论文,每篇的引用次数都至少达到了10次。
第二部分:如何计算?一个生动的例子
假设一位学者总共发表了6篇论文,其被引用的次数如下:
- 论文 A: 100次
- 论文 B: 50次
- 论文 C: 20次
- 论文 D: 12次
- 论文 E: 8次
- 论文 F: 3次
计算步骤:
- 将所有论文按被引次数,从高到低排序。 (如上例所示)
- 从上往下,找到这样一个临界点: 在这个点,论文的排名序号,开始大于其被引次数。H指数就是这个临界点之前的那个数字。
让我们来逐一检查:
- 第1篇论文,引用100次,100 ≥ 1,满足。
- 第2篇论文,引用50次,50 ≥ 2,满足。
- 第3篇论文,引用20次,20 ≥ 3,满足。
- 第4篇论文,引用12次,12 ≥ 4,满足。
- 第5篇论文,引用8次,但 8 < 5,不满足。
临界点出现在第5篇论文。因此,这位学者的H指数就是4。
第三部分:为什么H指数如此重要?
H指数之所以被广泛应用于各类学术评价中(如基金申请、职称评定),是因为它具备了以下优点:
- 综合性: 它避免了“唯数量论”或“唯引用论”的偏颇,一个高H指数,通常代表着该学者既有持续的产出,又有稳定的影响力。
- 稳定性: 它是一个累积性指标,不会因为一篇论文的引用数暴涨或暴跌而产生剧烈波动,更能反映一位学者长期的、稳定的学术贡献。
第四部分:在哪里可以找到H指数?
您可以在以下几个主流的学术平台上,轻松找到任何一位学者的H指数:
- 1. Google Scholar (谷歌学术): 这是最常用、也最全面的来源。只要一位学者创建了自己的Google Scholar Profile,其H指数就会在主页右侧被清晰地展示出来。由于Google Scholar的引文统计范围最广(包括书籍、学位论文等),其计算出的H指数通常是最高的。
- 2. Scopus: Scopus数据库会自动为被其收录的作者,创建个人档案(Author Profile),并自动计算其H指数。由于Scopus的数据库范围比Google Scholar更严格,其H指数通常会稍低。
- 3. Web of Science (WoS): 同样,Web of Science也会为其收录的作者计算H指数。因为WoS核心合集的筛选标准最为严格,所以在这里查到的H指数,通常是**最低的,但也被认为是最“保守”、最“核心”**的。
第五部分:H指数的局限性
尽管H指数非常有用,但它并非一个完美的指标。我们在使用时,也应了解其局限性:
- 学科差异: 不同学科的引用模式天差地别。一个生命科学领域的学者和一个历史学领域的学者,其H指数完全不具备可比性。
- 偏向资深学者: H指数是一个累积指标,会随着学者学术生涯的增长而自然增加,因此用它来直接比较一位青年学者和一位资深教授是不公平的。
- 无法反映“爆款”论文: 两位H指数同为10的学者,一位可能有1篇被引用上万次的论文,另一位可能最-高的引用也只有几十次。H指数无法体现这种差异。
结论 H指数,是现代学术评价体系中一个无法绕开的、极其重要的参考指标。它为我们提供了一个相对客观的、兼顾了“质”与“量”的视角,来评估一位学者的长期学术影响力。
然而,我们应始终铭记,任何单一的数字都无法完全定义一位学者的真正价值。一个全面的评价,还应包括其代表作的质量、在学术社区中的贡献、以及其研究工作的社会意义等多个维度。