 国际站
国际站 在计算机科学领域的EI国际学术会议中,审稿人往往具有极强的极客精神与怀疑态度。当你提出一种全新的算法或模型时,无论你在理论部分(Methodology)把公式写得多漂亮,最终决定论文能否被录用的,往往是实验与结果分析(Experiments and Results)这一章。
审稿人只相信数据。对于算法类论文而言,优秀的实验设计不仅是为了证明“我的方法有效”,更是为了证明“我的方法比别人的好”,且“我加的每一个模块都有用”。
以下是为计算机专业学者梳理的算法类论文实验部分标准写作框架。
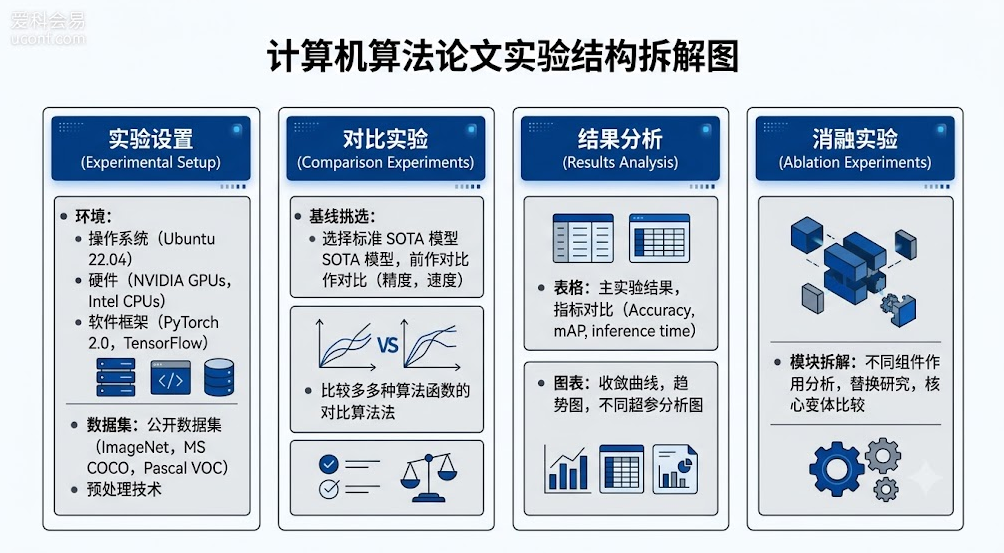
一、 实验设置(Experimental Setup):主打“完全可复现”
科学研究的基石是可复现性(Reproducibility)。在展示结果之前,必须老老实实地交代你的实验环境。这部分通常分为三个小节:
-
运行环境与硬件(Implementation Details):明确写出你使用的操作系统、编程语言版本(如 Python 3.8)、深度学习框架(如 PyTorch 1.10)以及最关键的硬件配置(如使用了几张 NVIDIA RTX 3090 GPU)。
-
数据集(Datasets):详细介绍你用于测试算法的数据集。强烈建议使用该领域公认的公开标准数据集,而不是自己私下伪造的数据。如果是自己采集的数据,必须详细说明采集方法和规模。
-
评价指标(Evaluation Metrics):告诉读者你用什么尺子来衡量算法的好坏。是准确率(Accuracy)、精确率(Precision)、召回率(Recall),还是算法的时间复杂度(运行耗时)或空间复杂度(内存占用)?列出这些指标的具体计算公式。
二、 基线对比(Baseline Comparison):挑选合格的“陪跑者”
为了证明你的算法优秀,你需要找几个对比对象,学术界称之为基线(Baselines)。挑选对比算法是极具策略性的环节。
-
不能只挑“软柿子”捏:如果你的对比对象全是五六年前的老算法,审稿人会立刻认为你的研究没有跟上最前沿的步伐。
-
经典与前沿并重:挑选2到3个该领域的“祖师爷”级别经典算法,再挑选2到3个近两年来发表在顶会上的 SOTA(State-of-the-Art,目前最优)算法。
-
公平竞技:必须强调所有对比实验都是在相同的数据集和硬件环境下跑出来的。如果你为了让自己的数据好看,故意压低对比算法的参数配置,这种学术不端极易被审稿人识破。
三、 数据展示与深度分析(Results Analysis):拒绝只报流水账
当跑出了漂亮的准确率后,很多新手只会写一句:“如表1所示,我们的方法比其他方法都好。”这种干瘪的描述是学术写作的大忌。
-
图表结合,重点加粗:用表格展示精确到小数点后两位的严谨数据,并把你算法取得的最优结果用粗体标出。对于随参数变化的趋势图,使用折线图更为直观。
-
写出“为什么好”:描述现象后,必须跟上分析。为什么你的算法在A数据集上领先很多,而在B数据集上优势不明显?是不是因为你的算法专门针对A数据集里的某种特征做了优化?审稿人希望看到你对算法底层的深刻理解,而不仅仅是汇报一个最高分。
四、 消融实验(Ablation Study):证明你没有“凑字数”
对于当今复杂的计算机算法(尤其是深度学习模型)来说,消融实验是不可或缺的灵魂环节。
当你在基础模型上增加了 A、B、C 三个创新模块,最终发现准确率提升了 5%。审稿人会问:这 5% 的提升,是不是全是模块 A 的功劳?模块 B 和 C 是不是毫无用处,纯粹是为了凑工作量写进去的?
消融实验就是要回答这个问题。你需要像做控制变量法一样,做几组额外的测试:
-
拿掉模块 A,看看性能掉多少。
-
拿掉模块 B,看看性能掉多少。
-
拿掉模块 C,看看性能掉多少。
通过数据证明,A、B、C 三个模块缺一不可,它们各自贡献了不同的性能提升。有了这部分,你的算法逻辑就形成了无懈可击的闭环。