 国际站
国际站 2月21日,Nature子刊正式发表题为“Auditing unauthorized training data from AI generated content using information isotopes”(基于信息同位素技术的黑盒大模型训练数据成员审计技术)的研究论文。论文第一作者为北京邮电大学计算机学院(国家示范性软件学院)特聘研究员齐涛,计算机学院(国家示范性软件学院)王尚广教授、香港科技大学谢悦琪助理研究员、清华大学黄永峰教授、与剑桥大学Nicholas D. Lane教授共同担任本文通讯作者。

以大语言模型为代表的人工智能的飞速发展,高度依赖于对海量人类生成数据的深度汲取,然而当前训练数据的获取普遍面临严峻的版权与隐私挑战:大量受保护的作品及敏感数据在未获授权的情况下被用于商业训练,开发者以模型性能提升的方式“隐性获利”,使得侵权行为极具隐蔽性。更为严峻的是,大模型的训练语料常被刻意遮蔽,数据权利人在面对仅提供接口服务的“黑盒”大模型时(用户只能访问模型生成内容),几乎无法发现侵权行为,更难以完成有效举证。因此,研究面向黑盒大模型的训练数据使用审计与证据验证技术,是推动AI合规治理、建立可执行的数据责任追溯机制、平衡技术创新与权利保护的必然要求。
针对上述挑战,本文首次揭示人工智能系统中的“信息同位素”机理,指出隐私数据中天然内嵌的微结构信息可在模型学习与生成过程中稳定保留并跨阶段传导,从而构成可追踪的隐式标识。在此基础上,构建信息同位素驱动的模型记忆量化理论,实现数据成员性的可计算表征与精确度量;提出跨模态推理引导的先验知识解耦与校准机制,系统剥离背景知识干扰;最终形成仅依赖模型输出的训练数据审计技术体系,突破了黑盒条件下大模型训练数据隐私与版权侵犯问题难检测的挑战,为大模型数据安全治理提供了新的理论基础与技术路径。
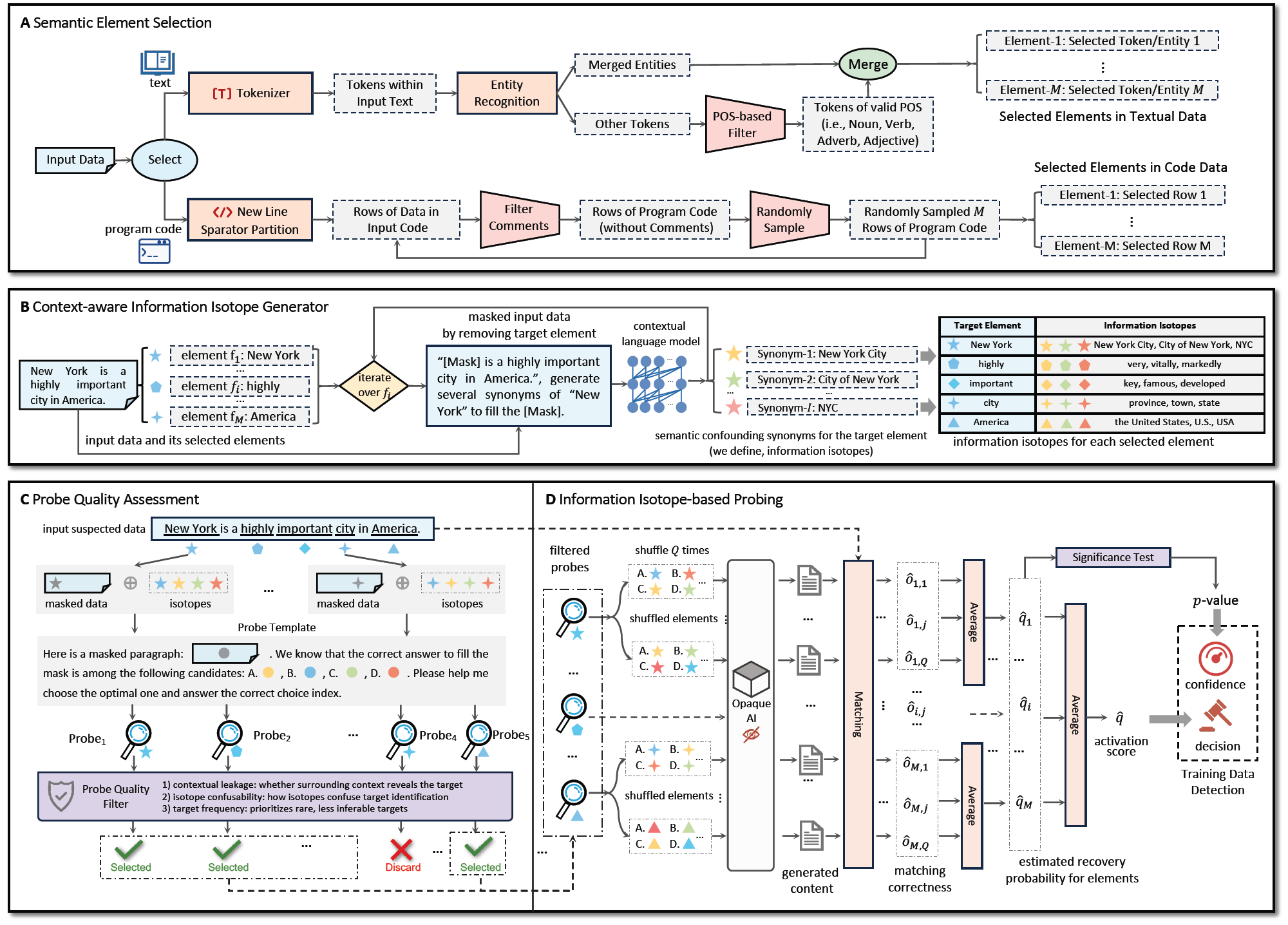
图1:算法流程图及关键技术说明
在覆盖当前 13 种主流大模型(如 GPT-4o、Claude、Gemini 等)与 6 类关键数据领域的系统评测中,本文所提算法以最高超过99%的检测准确率(p < 0.01)实现了对训练数据成员性的精准识别,整体性能显著优于现有相关方法。同时,该算法在对抗扰动与百万Token级长文本场景下仍保持稳定表现,展现出优异的鲁棒性与可扩展能力,充分验证了其在复杂 AI 系统中开展训练数据审计的实际应用潜力。
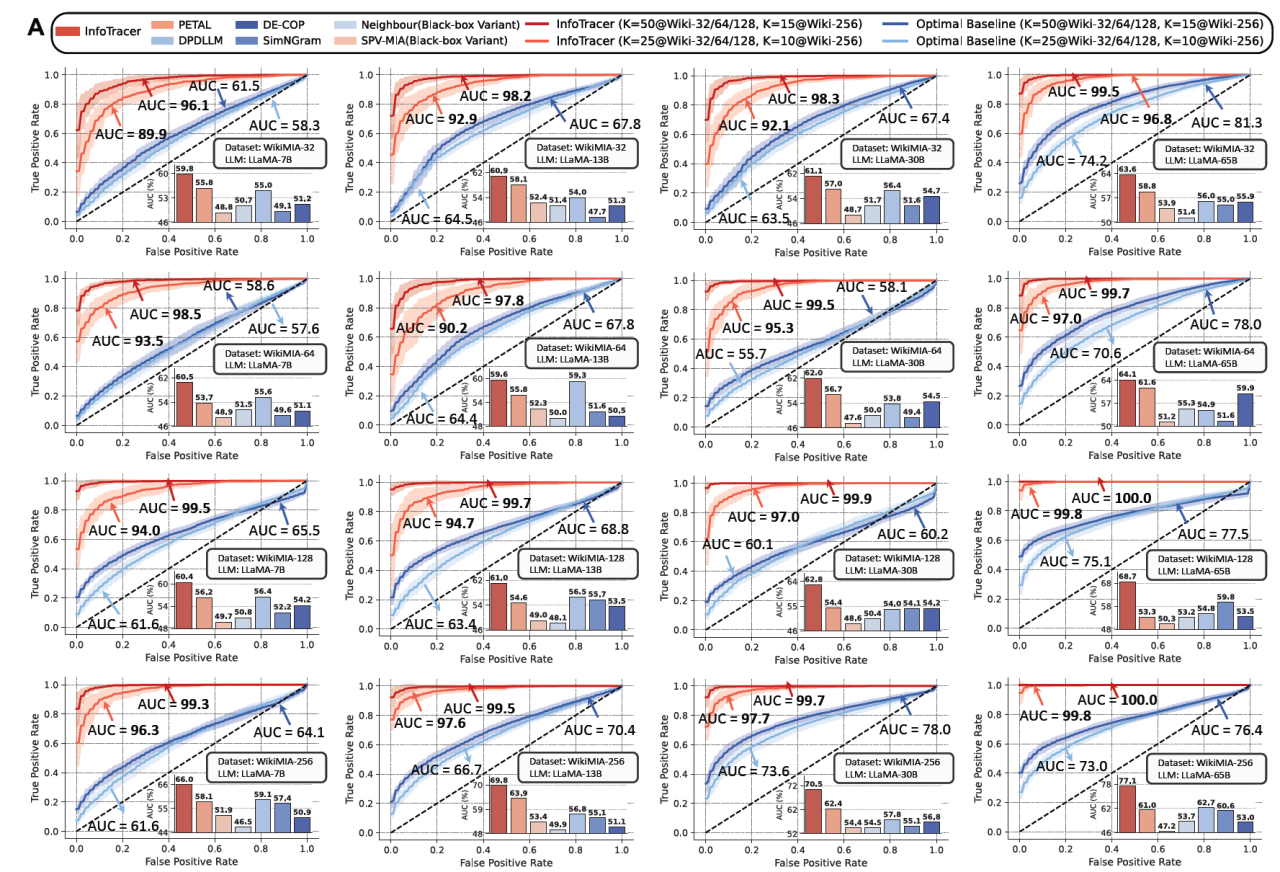
图2:核心性能评测结果
其中InfoTracer为本文所提方法
该成果为大模型时代的数据安全保护提供了可落地的技术路径,并从机理层面构建了黑盒条件下训练数据审计的系统化理论框架与方法范式,填补了数据可追踪性的关键空白,对完善大模型安全治理体系、推动可信人工智能发展具有重要意义。
论文链接: https://www.nature.com/articles/s41467-026-68862-x
来源:北邮计语,爱科会易仅用于学术交流,若相关内容侵权,请联系删除。