 国际站
国际站 很多新手查文献,就是把自己的论文题目直接复制到搜索框里,这样搜出来的结果不仅少,而且杂乱无章。
1. 拆解核心词与同义词 (Keyword Expansion)
不要搜长句,要搜“关键词组合”。例如你的题目是“短视频对大学生学习焦虑的影响”,你要拆解成三个维度,并寻找同义词:
-
维度 A (自变量): 短视频、抖音、TikTok、碎片化视频。
-
维度 B (因变量): 学习焦虑、学业压力、学习倦怠。
-
维度 C (研究对象): 大学生、高校学生、青年群体。 在检索时,使用 OR (或者) 和 AND (并且) 将这些词组合起来,搜索结果的覆盖面会呈指数级扩大。
2. 知网的“降维打击”:高级检索与来源筛选
知网里的文章质量参差不齐,为了保证你引用的文献有学术说服力:
-
必用高级检索: 限定“篇关摘(篇名、关键词、摘要)”包含你的核心词,而不是全文包含(全文包含会搜出大量沾边但不相关的无效文献)。
-
卡死来源期刊: 在侧边栏的“来源类别”中,勾选 CSSCI、北大核心、CSCD。本科论文如果能大量引用这些核心期刊,导师在格式审查环节就会给你打高分。
3. Google Scholar 的“滚雪球法” (Citation Tracking)
这是学术界最常用的绝招。当你偶然发现了一篇和你研究主题极其吻合、质量极高的“神仙论文”时:
-
不要停!立刻看这篇论文的 “参考文献 (References)”(向过去找:看看这篇好文章是站在哪些巨人的肩膀上写出来的)。
-
在 Google Scholar 中搜索这篇论文,点击下方的 “被引用次数 (Cited by xxx)”(向未来找:看看这篇文章发表后,又有哪些最新的牛人引用了它)。 通过这一篇“种子文献”,你可以迅速滚出一个高质量的文献家族。
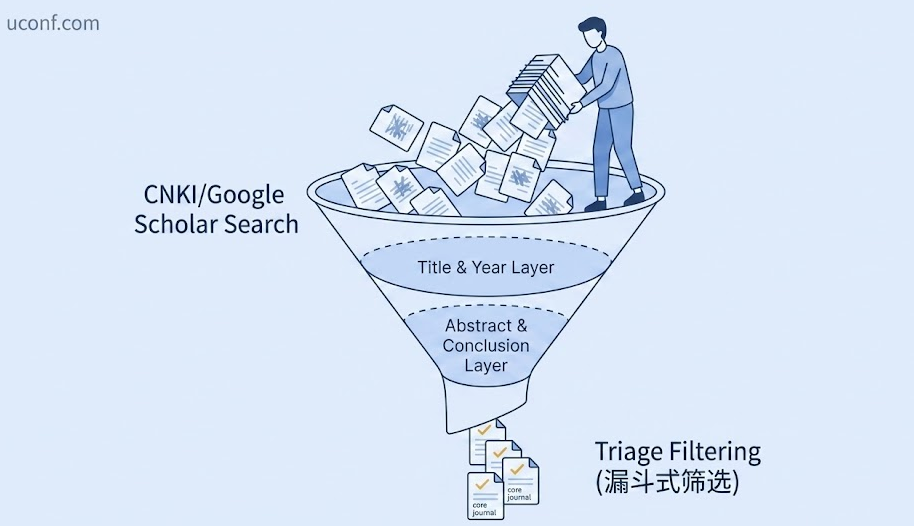
三、 高效阅读篇:5 分钟“漏斗式”文献甄别法
下好了几十篇 PDF,绝对不要从引言的第一段开始读!正确的阅读姿势是像 HR 筛简历一样,采用“漏斗淘汰制”。
第一关:看标题与发表年份 (耗时:10 秒)
-
看什么: 标题是否包含你的核心变量?如果是社科类、经济类文章,年份是否太老(超过 5 年的实证数据通常参考价值极低)?
-
决策: 太老或标题完全不沾边,直接淘汰。
第二关:读摘要 (Abstract) 与结论 (Conclusion) (耗时:2 分钟)
-
看什么: 这是最核心的一步。摘要是整篇论文的微缩版,通常包含“背景、方法、结果、意义”。看完摘要,立刻跳到文章最后一页看 Conclusion(结论)。
-
问自己: 它的研究对象和我的吻合吗?它得出的结论,对我的论文有支撑作用吗?或者它的结论跟我完全相反,我可以用来做对比批判吗?
-
决策: 如果摘要显示它研究的是“中学生”而不是你要的“大学生”,或者结论极其空泛,立刻淘汰。
第三关:看图表 (Figures & Tables)与小标题 (耗时:1 分钟)
-
看什么: 快速滑过正文,看看各段的小标题结构。如果是理科或实证论文,直接看图表。优秀的论文,图表本身就能说话。看看它的问卷维度是怎么划分的,或者实验数据长什么样。
-
决策: 如果图表清晰,数据对你有启发,保留。
第四关:精准细读 (耗时:半小时以上)
-
经过前三关的无情淘汰,10 篇论文里可能只剩下 2 到 3 篇。恭喜你,这几篇就是你的“核心文献”。
-
此时,你才需要坐下来,去深读它的 引言 (Introduction)(看它是怎么引出问题的)和 研究方法 (Methodology)(学习它的量表是怎么设计的,模型是怎么建的)。
四、 结语
在学术的海洋里,文献检索与阅读并不是一头扎进水里拼命游,而是先站在高处用望远镜观察,找到最精准的航线。学会利用高级检索过滤噪音,用“漏斗阅读法”保护自己的时间精力。当你不再被海量文献裹挟,能够迅速判断出一篇论文的真实价值时,你就已经跨过了学术写作最高的那道门槛。