 国际站
国际站 2月16日凌晨,OpenAI在官网发布了创新性文生视频模型——Sora。
从OpenAI在官网展示的Sora生成视频的效果来看,在生成视频质量、分辨率、文本语义还原、视频动作一致性、可控性、细节、色彩等方面非常好!
特别是可以生成最长1分钟的视频!超过Gen-2、SVD-XT、Pika等主流产品。
Sora生成案例展示:
以下视频全部由Sora生成,感叹一下,效果、时长等方面真的太强了!
Sora生成的1分钟视频:提示词,一位时尚女性走在街道上,街道上到处是温暖的霓虹灯和动画城市标志。她身穿黑色皮夹克、红色长裙和黑色靴子,手拿黑色钱包;她戴着太阳镜,涂着红色唇膏。她走起路来自信而随意。街道潮湿而反光,与五颜六色的灯光形成镜面效果。许多行人走来走去。

再比如,AI 想象中的“龙年春节”,Sora能形成紧跟舞龙队伍抬头好奇的儿童,也能生成海量人物角色各种行为。

输入 prompt(提示词):一位 24 岁女性眨眼的极端特写,在魔法时刻站在马拉喀什,70 毫米拍摄的电影,景深,鲜艳的色彩,电影效果。

输入 prompt(提示词):一朵巨大、高耸的人形云笼罩着大地。云人向大地射出闪电。

输入 prompt(提示词):几只巨大的毛茸茸的猛犸象踏着白雪皑皑的草地走近,它们长长的毛茸茸的皮毛在风中轻轻飘动,远处覆盖着积雪的树木和雄伟的雪山,午后的阳光下有缕缕云彩,太阳高高地挂在空中距离产生温暖的光芒,低相机视角令人惊叹地捕捉到大型毛茸茸的哺乳动物,具有美丽的摄影和景深效果。

通过这些动图来看,Sora不仅可以在单个视频中创建多个镜头,而且还可以依靠对语言的深入理解准确地解释提示词,保留角色和视觉风格。
Sora介绍
目前,文生视频领域因为帧间依赖处理、训练数据、算力资源、过拟合等原因,一直无法生成高质量的长视频。
而Sora最大技术突破是,可以在保持质量的前提下,生成1分钟的视频,在业内非常罕见。这也再次展示了OpenAI在大模型领域超强的技术研发能力。
Sora是一种扩散模型,主要通过静态噪音的视频开始生成视频,然后再通过多个步骤去除噪音,逐渐转换视频。
Sora与ChatGPT一样采用的是Transformer架构,并使用了DALL-E 3中的重述技术,是一种为视觉训练数据生成高精准描述性的字幕。所以,Sora在生成视频过程中精准还原用户的文本提示语义。
功能方面,除了文本生成视频之外,Sora还能根据图像生成视频,并能准确地对图像内容进行动画处理。也能提取视频中的元素,对其进行扩展或填充缺失的帧,功能非常全面。
OpenAI强调,“Sora是能够理解和模拟现实世界的模型的基础,我们相信这一功能将成为实现通用人工智能(AGI)的重要里程碑。”
官方博客中,OpenAI 称 Sora 的目标是「理解和模拟现实」,这也是是英伟达 Omniverse 多年来押注的未来。看到 Sora 的能力,英伟达高级科学家,AI Agent 负责人 Jim Fan 盛赞其强大模型背后的技术突破。
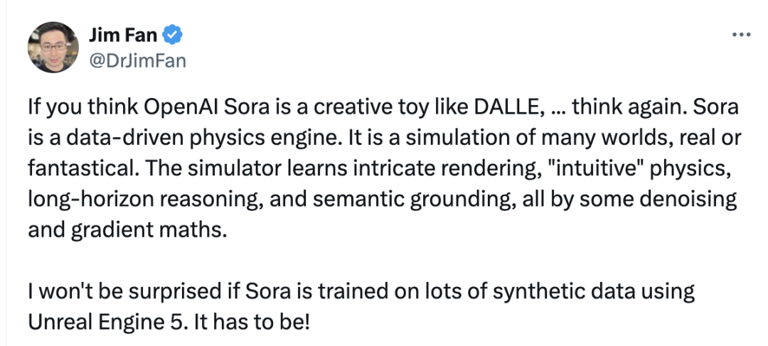
Jim Fan 在 X 社交媒体发表上述观点|来源:twitter.com
他称,「如果你认为 OpenAI Sora 是一个像 DALLE 一样的创意玩具……再想想。Sora 是一个数据驱动的物理引擎,是对现实或幻想世界的模拟。这一模拟器通过去噪和梯度数学,来学习复杂渲染、『直觉』物理(「intuitive」physics)、长视野推理(long-horizon reasoning)和语义基础。」
在其背后的技术实现上,Jim Fan 认为,Sora 一定使用了 Unreal Engine 5 生成的大量合成数据来训练。
Sora 模型的训练数据等细节,请移步OpenAI技术论文页面:
论文链接:Video generation models as world simulators (openai.com)
OpenAI同时指出,当前的模型还存在弱点。它可能难以准确模拟复杂场景中的物理现象,也可能无法理解具体的因果关系,还可能混淆提示中的空间细节。在精确描述随着时间推移而发生的事件方面,该模型也可能存在困难。
在安全性方面,OpenAI称,他们正与red teamers(错误信息、仇恨内容和偏见等领域的专家)合作,后者将对模型进行对抗性测试。OpenAI还在开发有助于检测误导性内容的工具,例如检测分类器,它可以分辨出视频是否由Sora生成。
目前,red teamers可以使用Sora评估关键领域的危害或风险。一些视觉艺术家、设计师和电影制片人也可以访问并反馈意见,OpenAI由此可以了解如何改进模型,使其为创意专业人士提供有利帮助。
OpenAI称,将尽早分享研究进展,以便开始与其他人员合作并获得反馈,同时让公众了解人工智能的发展前景。
Sora的发布引发了业内广泛讨论。有人工智能专家和分析师表示,Sora视频的长度和质量超出了迄今为止所见的水平。伊利诺伊大学厄巴纳-香槟分校信息科学教授Ted Underwood称:“我没想到在接下来的两到三年内还会出现这种持续、连贯的视频生成水平。”
但牛津互联网研究所客座政策研究员Mutale Nkonde担心,这些工具可能会嵌入社会偏见,对人们的生活产生影响,并能将仇恨或令人痛心的现实事件通过文字描述变成逼真的镜头。
总结:AI 行业都“卷”起来了
除了Sora之外,2月16日凌晨,计划全面超越GPT的谷歌,宣布推出 Gemini 1.5,最高可支持10,000K token超长上下文的Gemini 1.5 Pro,也是谷歌最强的MoE大模型。大语言模型领域从此将进入一个全新的时代!1,000,000 token超超超长上下文,全面碾压GPT-4 Turbo。在上下文窗口方面,此前的SOTA模型已经「卷」到了200K token(20万)。如今,谷歌成功将这个数字大幅提升——能够稳定处理高达100万token(极限为1000万token),创下了最长上下文窗口的纪录。

随后。Meta也公布了一种视频联合嵌入预测架构技术V-JEPA。V-JEPA 并不是一个生成模型。Meta 的研究人员说,V-JEPA 在使用视频遮蔽进行预训练后,"擅长检测和理解物体之间高度细致的互动"。这项研究可能会对 Meta 和更广泛的人工智能生态系统产生重大影响。

2024年开年,AI 大模型技术进展全面加速,视频、图像、文本生成能力比一年前大大增强。
如果说,2023年还是“AI 图文生成元年”的话,今年,OpenAI将推动行业进入”AI视频生成元年”。

来源:OpenAI,爱科会易仅用于学术交流