 国际站
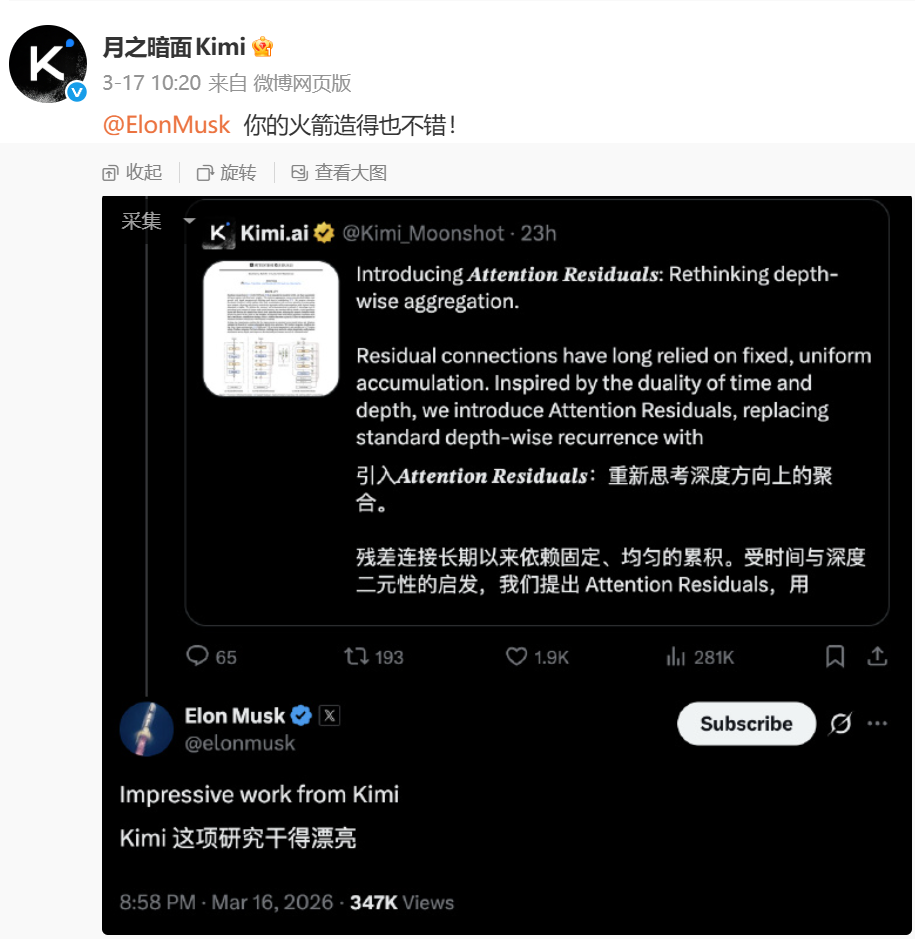
国际站 近日,中国人工智能公司月之暗面(Moonshot AI)Kimi团队发表一篇题为Attention Residuals: Rethinking depth-wise aggregation重磅论文,团队对大模型十年没有变化的核心结构残差连接行重新设计,算力效率提升了1.25倍,在AI界引发震动。特斯拉CEO埃隆·马斯克(Elon Musk)在社交媒体上公开点赞该研究成果,评价其为“来自Kimi的亮眼工作(Impressive work)”。
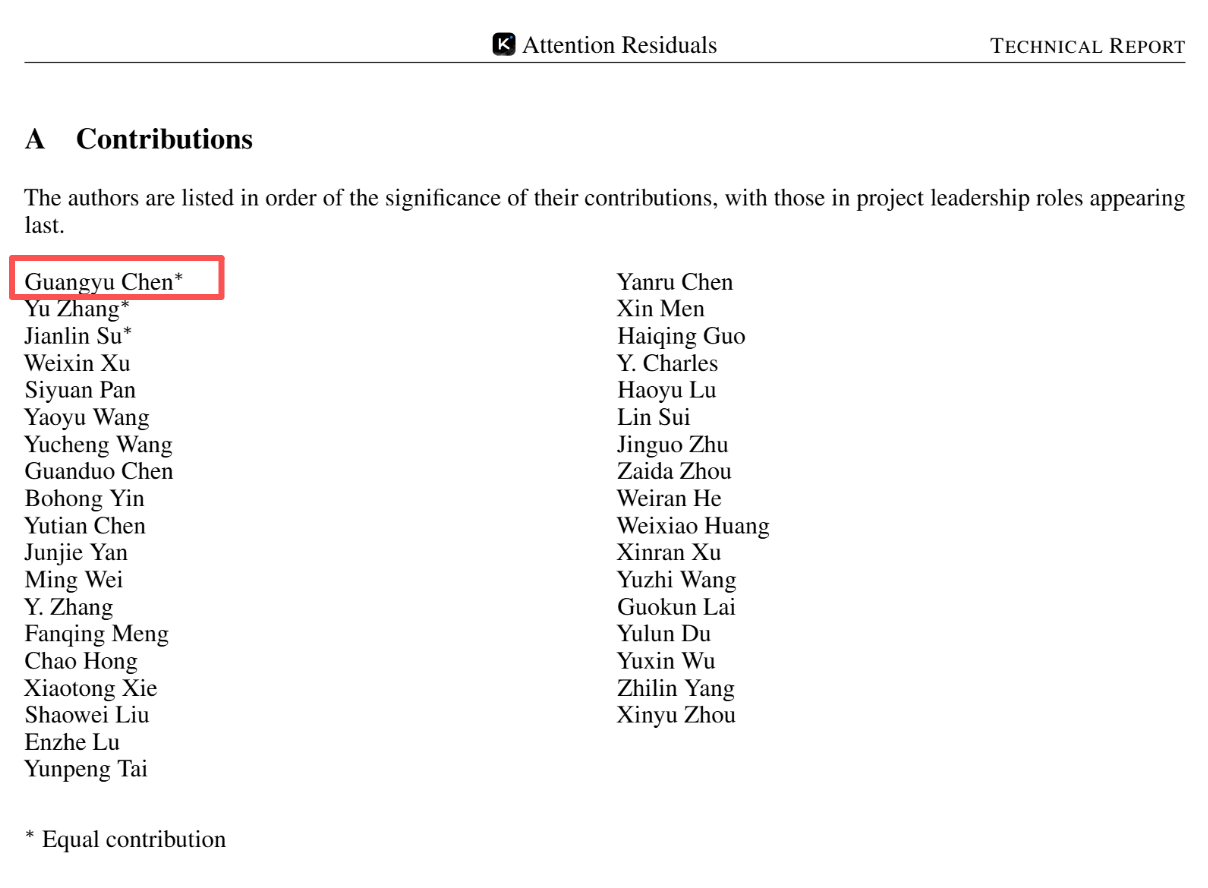
论文作者是来自月之暗面的数十名研究员,对项目贡献最突出的三位研究员分别是陈光宇、Yu Zhang以及 Jianlin Su。其中,值得注意的是,第一作者陈广宇是一名年仅 17 岁、加入团队仅 5 个月的高三学生,他虽然还未高中毕业,但已经从“学生”变成“一线贡献者”。

 Kimi团队此次对大模型十年没有变化的核心结构残差连接行重新设计,使每一层能够选择性地关注此前各层输出,而非统一求和,48B模型训练效率提升1.25倍,被行业解读为提前预告了下一代模型的关键模块。
Kimi团队此次对大模型十年没有变化的核心结构残差连接行重新设计,使每一层能够选择性地关注此前各层输出,而非统一求和,48B模型训练效率提升1.25倍,被行业解读为提前预告了下一代模型的关键模块。
论文介绍了一种名为 Attention Residuals (AttnRes) 的全新深度网络架构组件,它重构了 Transformer 模型在深度方向上的信息流动方式 。传统残差连接采用固定权重进行信息累加。而这种方法引入了学习到的、依赖于输入内容的 softmax 注意力机制,这种设计赋予了神经网络在每一层动态检索和选择性聚合所有历史层输出的能力,完成了在“深度”维度上从线性循环向自注意力的范式转变。
该方法已经在 Kimi Linear 架构中得到了验证。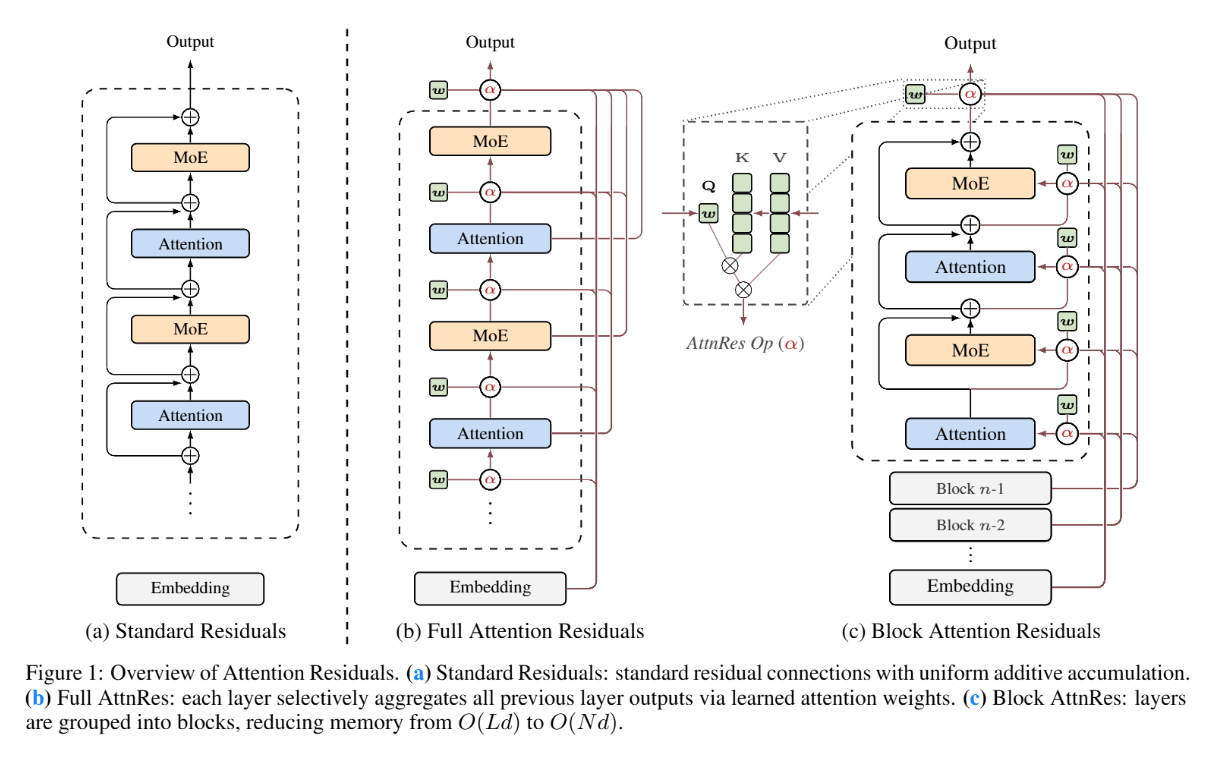
月之暗面是2023年3月成立的AI企业,由清华校友杨植麟等创立,核心产品Kimi大模型在国际榜单上多次挑战GPT-4/Claude等大模型,被誉为中国“AI四小虎”之一。
论文第一作者陈广宇是深圳一所国际学校的高三学生,预计今年6月毕业。其社交媒体信息显示,他已拥有顶尖竞技编程背景,参加过美国计算机奥林匹克竞赛铂金组比赛,在Kimi内部拿下48小时“黑客马拉松”比赛冠军。
从2025年11月至今,陈广宇在Kimi担任机器学习研究员,参与中国最顶尖的开源大模型的核心研发,已经从“学生”变成“一线贡献者”。
此前,陈广宇入选罗德信托的高潜力未来领袖计划,这是面向全球15–17岁潜力青年的选拔计划,他还在美国顶尖小型实验室Tilde Research做过AI研究。
对陈广宇而言,17岁以第一作者身份主导Kimi这样顶级独角兽的核心架构论文,堪称“硅谷震动级”事件,也让全球AI圈注意到“中国高中生已经在做前沿架构创新”。
陈广宇说,这样的论文太可能由一个人写出来,kimi的成员都有投入,论文署名的前三位作者做出的都是同等贡献,希望不要只关注个人。
论文链接:
https://github.com/MoonshotAI/Attention-Residuals/blob/master/Attention_Residuals.pdf
来源:月之暗面、X等,爱科会易仅用于学术交流,若相关内容侵权,请联系删除。